Results for the ultrametric tree-based, explainable, solar-powered language model.
These charts update each day.
This animation uses a tiny, inspectable decision tree to predict a
next word from a sentence context. The default sentence comes from
../papers/ultratrees/ultratrees.tex.
Rule semantics are illustrative and intentionally human-readable (not the production model).
?
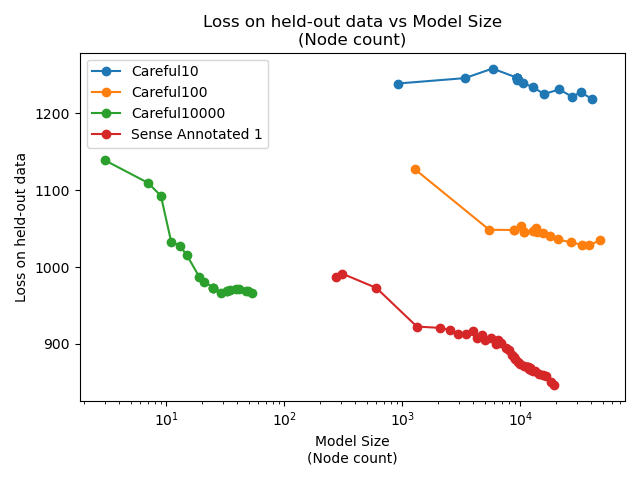
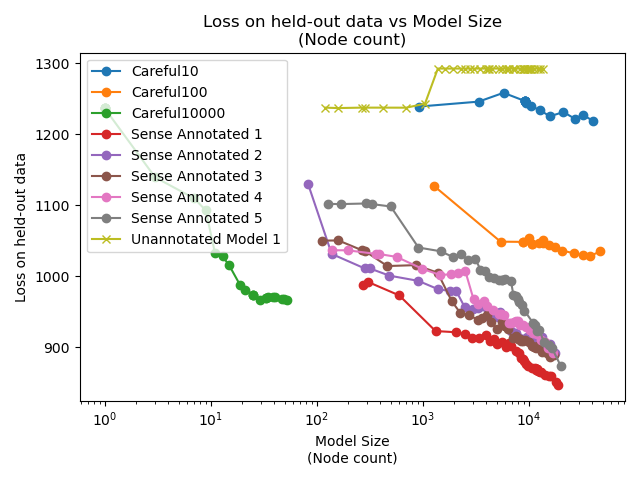
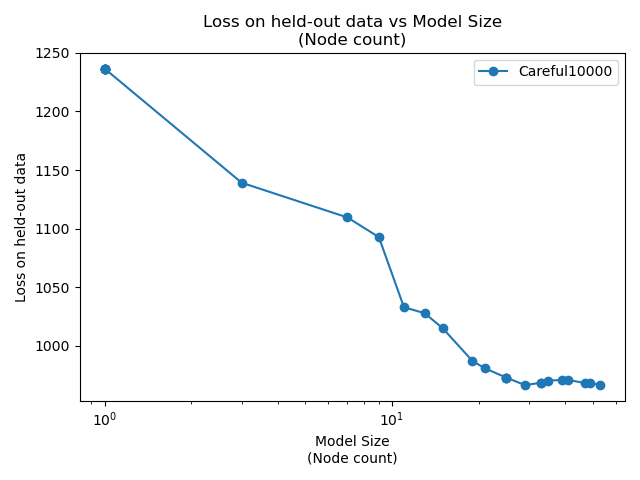
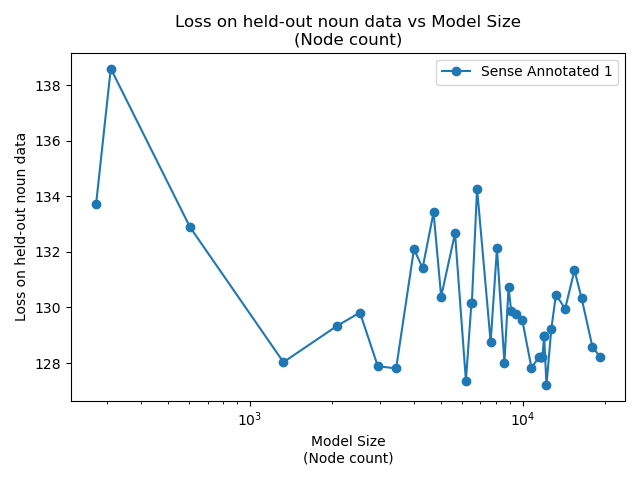
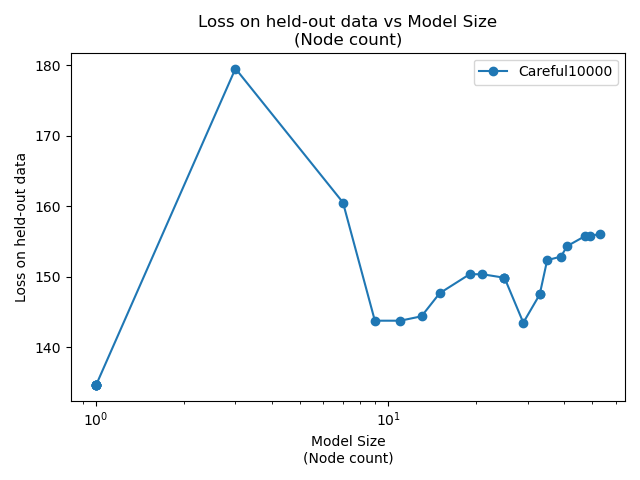
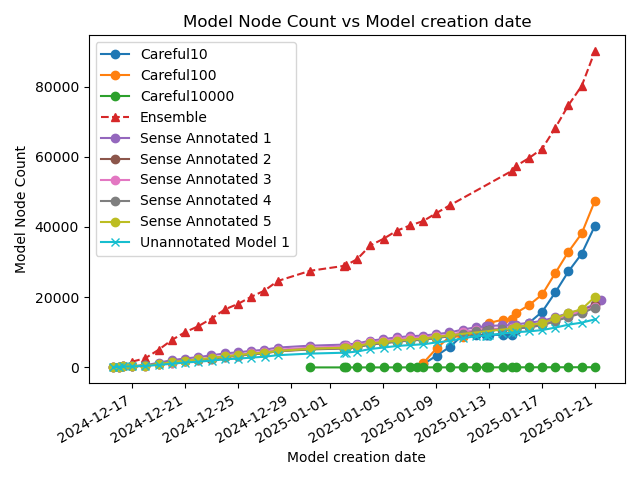
Training up an ultrametric tree by finding the optimal split at each step is computationally prohibitive. We can only subsample. Each order of magnitude increase in carefulness is roughly three orders of magnitude more compute time required. "Sense Annotated 1" is the alias of the first training of Careful1000, which seems like a reasonable compromise. It requires about 100 times as many nodes to achieve the same result as Careful10000, but it can train 1000 times faster.
Careful100 and Careful10 are much, much faster to train, but there's a threshold somewhere between Careful100 and Careful1000 where there are too many bad choices. It's open question what that threshold is, and why a threshold even exists.
The key question that this work set out to answer was whether sense annotation, and indeed, the whole idea of synergistic semantic and statistical models were worth exploring.
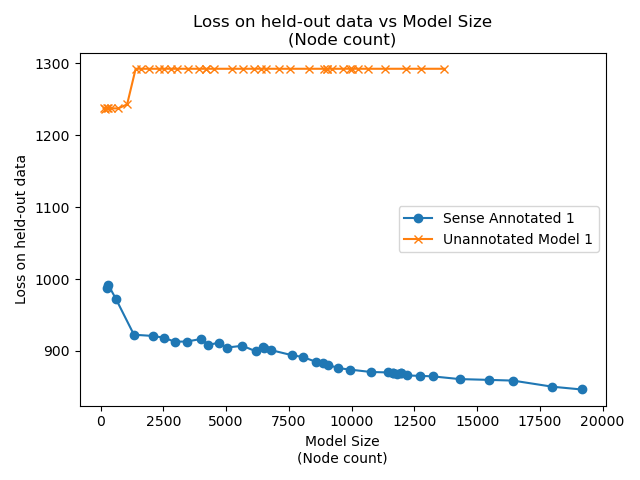
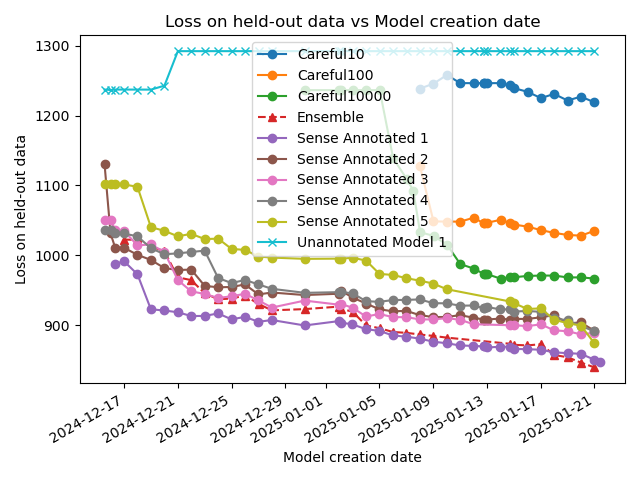
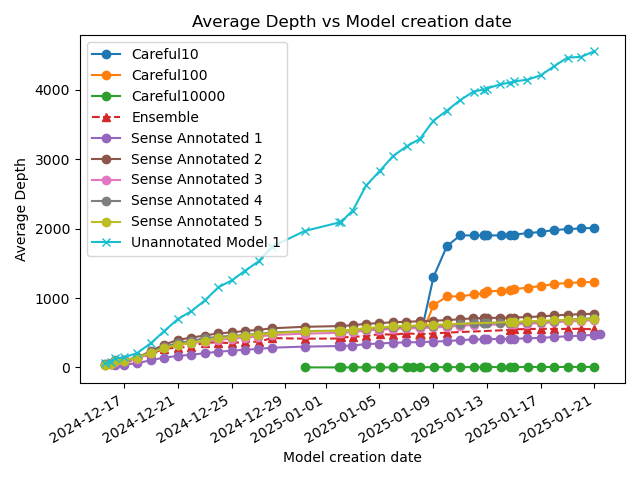
The "Unannotated Model 1" can be seen as being a baseline statistical model. It's equivalent to a one-hot encoded decision tree. The sense annotated model's learning generalises where the unannotated model is overfitting very early.
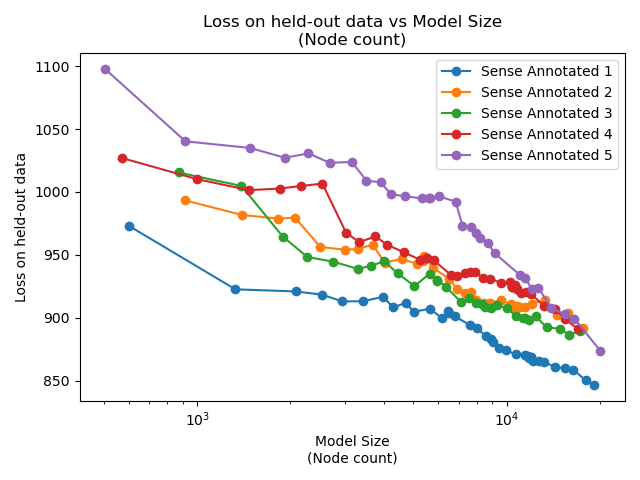
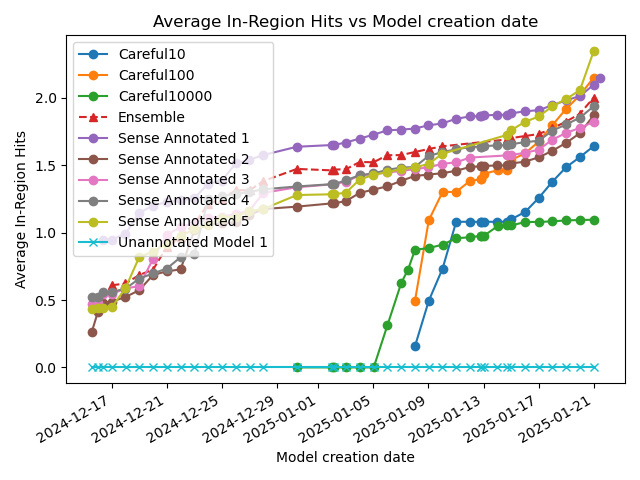
Broadly speaking, re-training on the same data yields similar results. Loss on the hold-out training data goes down, roughly linearly with the logarithm of the number of nodes in the model. Note that these are only sorted by time (the model that was trained first). It's just co-incidence that model 1 is the best and model 5 the worst.
Even the worst model is doing much better than the unannotated model. The probability of this happening by chance is 1/32, which is equivalent to a p-value of 0.03.
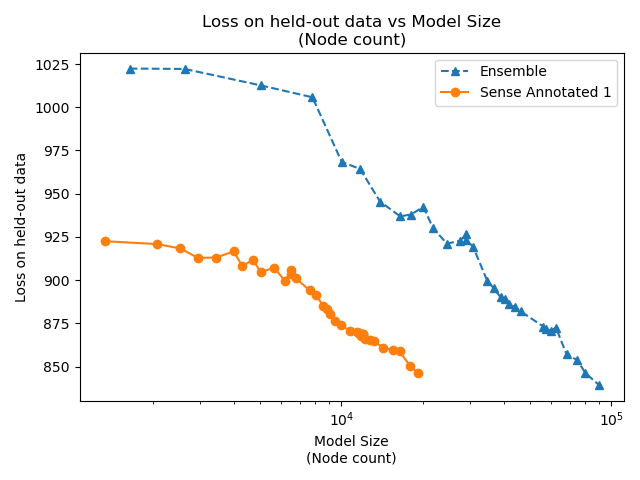
Ensembling doesn't work. For the same parameter count the loss is worse.
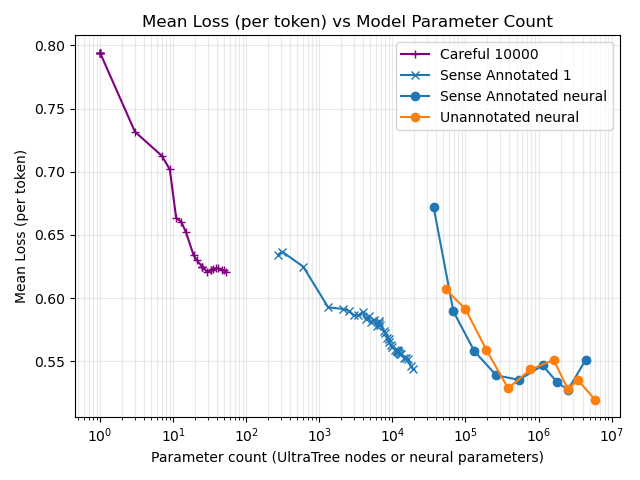
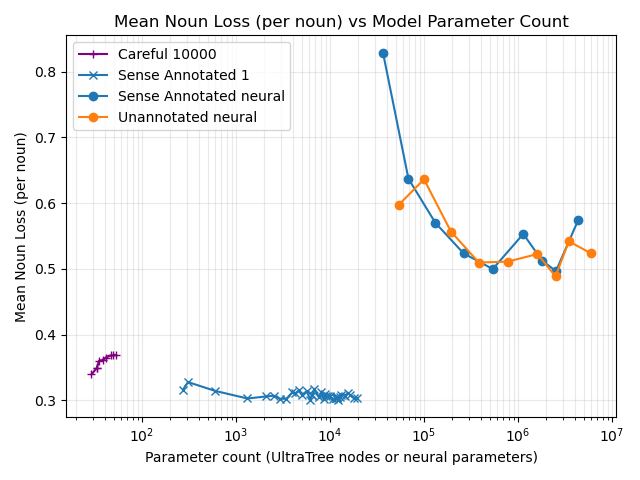
This compares the UltraTree loss curves (shown here for Careful10000 and Sense Annotated 1) against neural baselines, plotting everything against "parameter count" (UltraTree node count vs neural trainable parameters). Parameter-efficiency depends strongly on the UltraTree training regime, so this plot should be read as a comparison of these specific runs, not as a fundamental limit.
Weirder is that here sense annotation makes barely any difference to the neural network models.
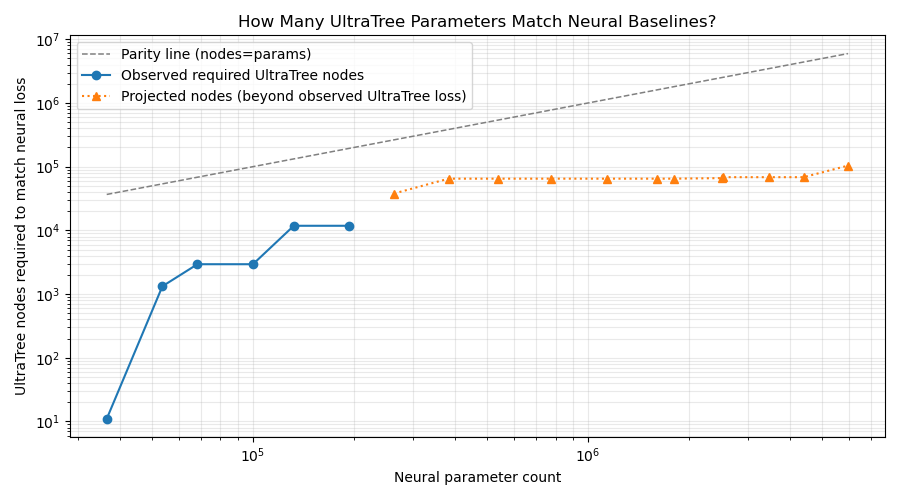
This chart answers: for a given neural parameter budget, how many UltraTree nodes are needed to match the best neural mean-loss result (loss per token). Solid points are directly observed in evaluation data; dotted points are extrapolated because neural loss is better than the best observed UltraTree loss. The UltraTree curve here is taken from the loss frontier across all UltraTree training regimes.
Overall and per-carefulness estimates:
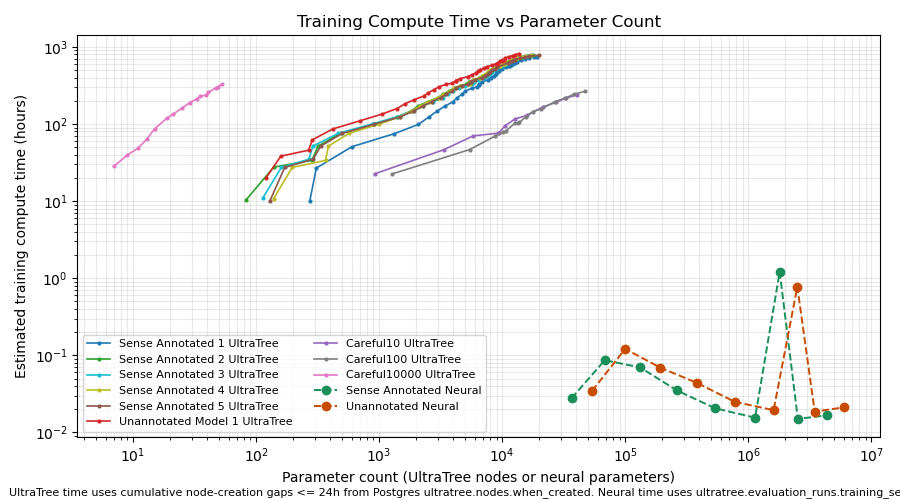
This compares estimated training compute time against parameter count
for both systems. For UltraTree, time comes from node-creation
timestamps in Postgres (ultratree.nodes.when_created) with
a 24-hour active-gap cutoff. For neural models, time comes from recorded
training time
(ultratree.evaluation_runs.training_seconds).
Overall and per-carefulness timing comparisons:
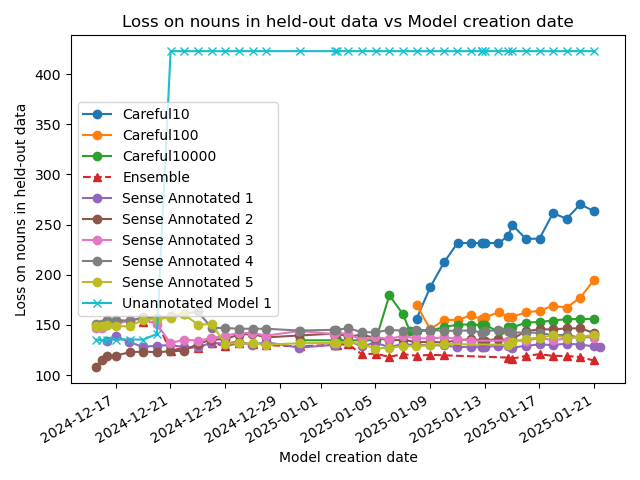
Instead of looking at the total loss over all parts of speech, we would expect that nouns would get the most benefit from having sense annotation into a hierarchy.
But the data shows the exact opposite: as we train, we are increasing the loss on nouns, which means that the loss on all other parts of speech much be dropping even more rapidly.
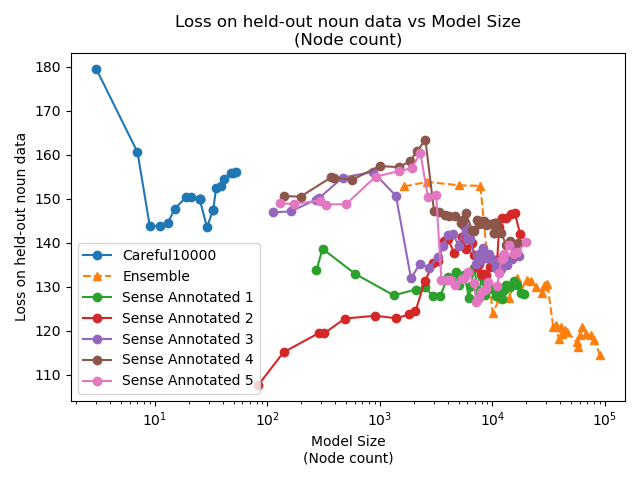
We do see that the ultratree models soundly outperform neural network models on nouns though. Neural networks are behaving as one would expect: larger models have more generalised learning.
Theory: the ultrametric models mostly predict nouns, because nouns
are the most common part of speech in the corpus, and they can group
parts of speech together into an aggregate. The neural network mostly
predicts punctuation, since it has no way of aggregating parts of speech
together without internalising rules of grammar. The
.'' character is the most common word'' in the corpus, so
all else being equal, it will get predicted more often.
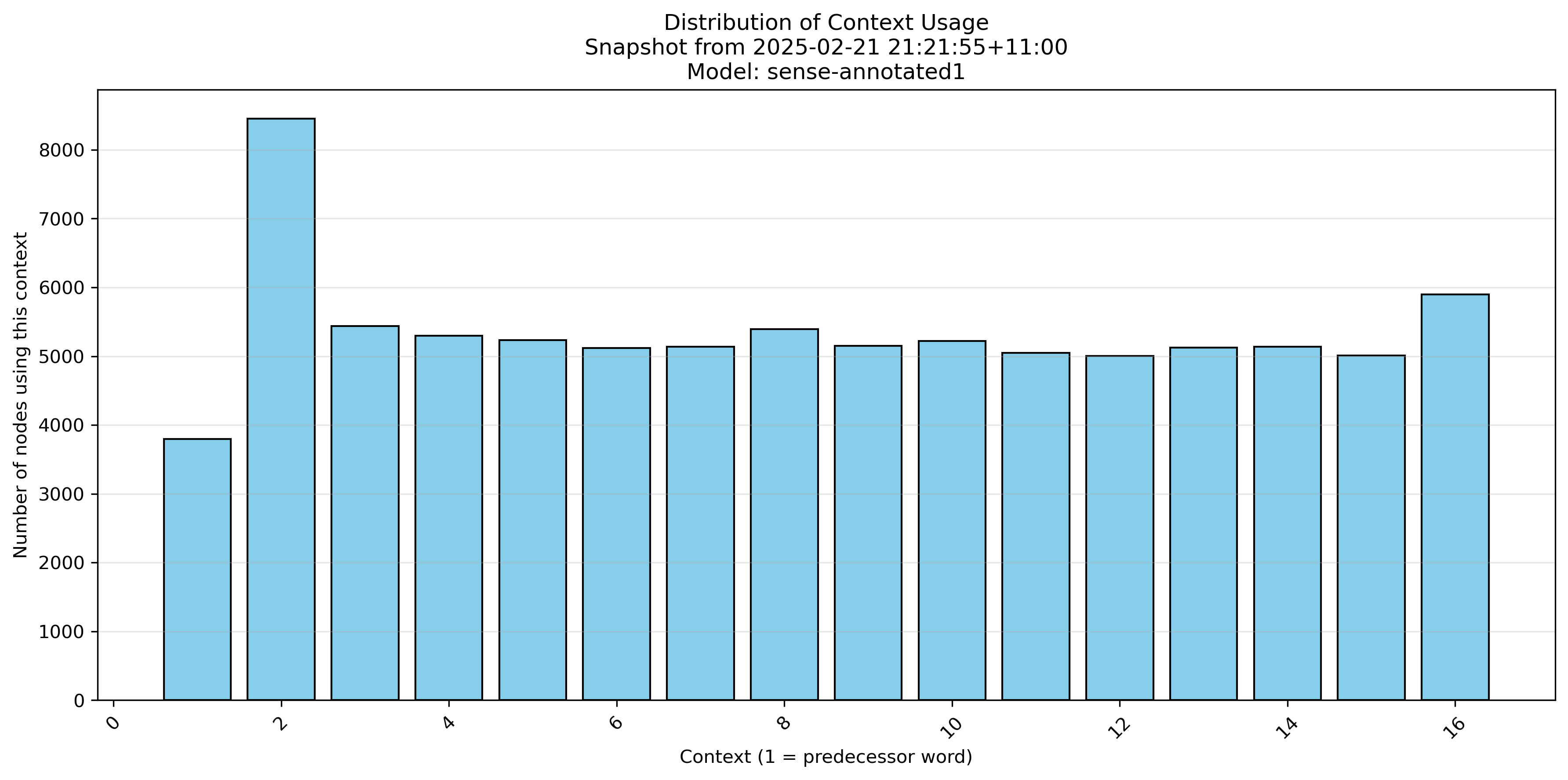
We can see which contexts get used for node splitting. (This is not the same as asking which nodes get used the most often in inference.)
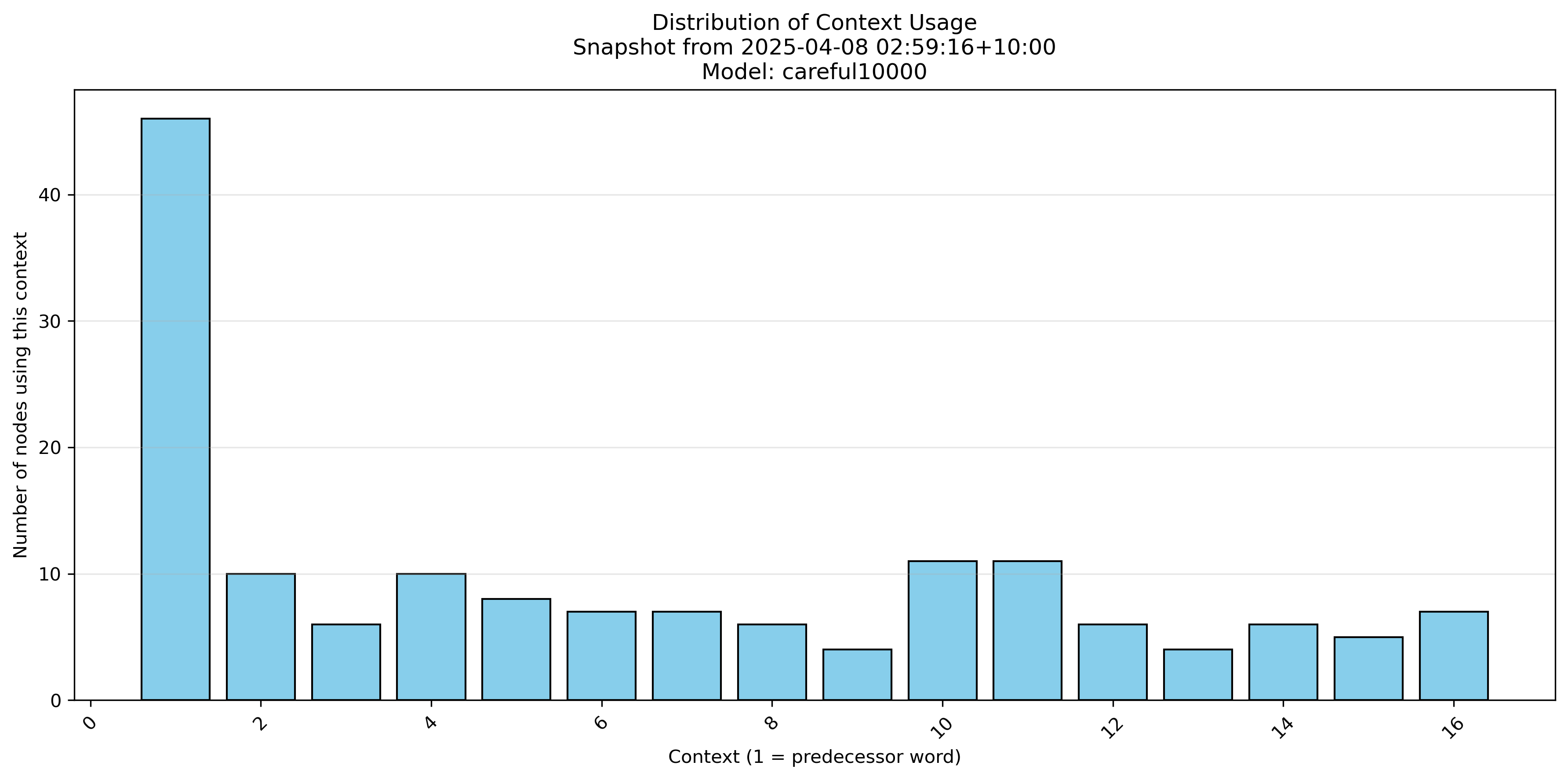
go/ultrametric-trees/bin/*)scripts/*.py and
python/results/*.py)psql and a PostgreSQL instanceULTRATREE_DATABASE_URLIf you use config/ultratree.env locally:
set -a
source config/ultratree.env
set +aDownload the mini dump:
curl -LO https://datadumps.ifost.org.au/ultratree/ultratree-mini-latest.pgdump.zst
zstd -d ultratree-mini-latest.pgdump.zst -o ultratree-mini.pgdumpRestore it into an empty database:
createdb ultratree_mini
pg_restore --no-owner --no-privileges -d ultratree_mini ultratree-mini.pgdump
psql ultratree_mini -c "CREATE EXTENSION IF NOT EXISTS pgcrypto;"
export ULTRATREE_DATABASE_URL="postgresql://.../ultratree_mini"
export ULTRATREE_SCHEMA="ultratree_mini"Training writes directly to Postgres. The key flags are the dataset to train on and the model name to give the run:
cd go/ultrametric-trees
make
./bin/train \
--database-url "$ULTRATREE_DATABASE_URL" \
--schema "$ULTRATREE_SCHEMA" \
--dataset sense-annotated-training-dataframe \
--model-name careful10 \
--carefulness 10 \
--max-nodes 101cd go/ultrametric-trees
./bin/evaluatemodel \
--database-url "$ULTRATREE_DATABASE_URL" \
--schema "$ULTRATREE_SCHEMA" \
--run-description "careful10 (example)" \
--model careful10 \
--dataset sense-annotated-test-dataframe \
--limit 200./scripts/build_site_from_postgres.sh --schema "$ULTRATREE_SCHEMA"
open site/dist/index.html # macOSOr serve locally:
python3 -m http.server --directory site/dist 8000